☁️ Gemini 3 Pro vs Claude 4.5 Sonnet 懶人包
想快速了解 Gemini 3 Pro 與 Claude 4.5 Sonnet 的核心差異?這份 AI 比較懶人包整理了兩大模型的關鍵優勢,幫助你在 3 分鐘內做出明智選擇。
| 評測項目 | Gemini 3 Pro | Claude 4.5 Sonnet |
|---|---|---|
| Intelligence Index | 73 分(全球第一) | 70 分(全球第二) |
| 上下文長度 | 1M token 輸入 | 200K token 標準 |
| 程式碼能力 | SWE-bench 76.2% | SWE-bench 72.7% |
| API 成本 | $2.00/百萬 token | $3.00/百萬 token |
| 最適用途 | 多模態、科學推理 | 創意寫作、中文處理 |
什麼是 Gemini 3 Pro?2025 年最強 AI 模型全面解析
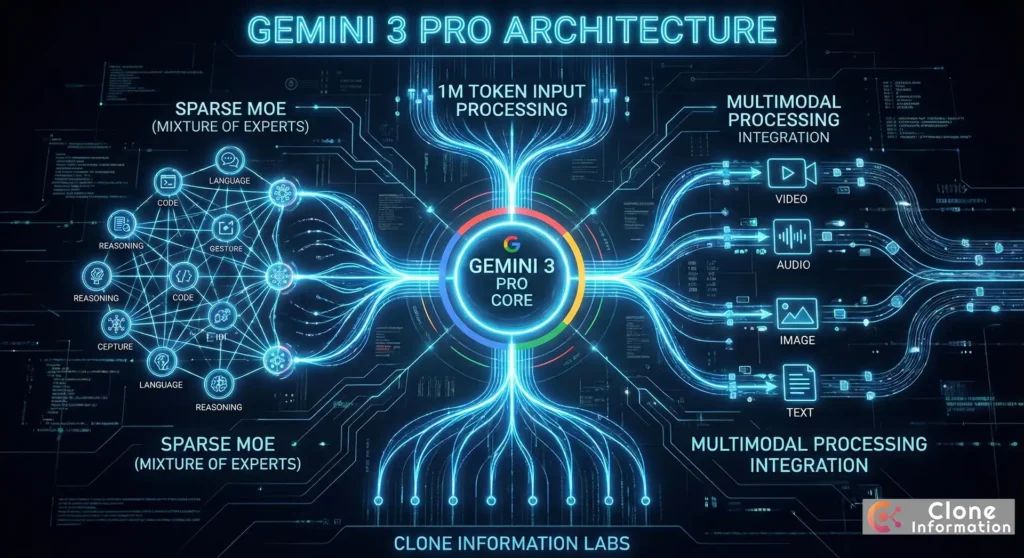
Gemini 3 Pro 是 Google DeepMind 於 2025 年 11 月 18 日正式發布的新一代大型語言模型,採用稀疏混合專家(Sparse MoE)架構,支援高達 1M token 的輸入上下文,是目前業界最強大的 AI 系統之一。
根據獨立評測機構 Artificial Analysis 的數據,Gemini 3 Pro 以 73 分的 Intelligence Index 評分登頂全球第一,成為有史以來首個突破該指標領先地位的 Google 模型。這項突破不僅代表技術的飛躍,更標誌著 AI 比較 版圖的重大洗牌。
在克隆資訊實驗室的實測中,我們發現 Gemini 3 Pro 在處理複雜的多模態任務時展現了驚人的穩定性。無論是分析影片內容、理解圖表數據,還是執行長篇文檔的綜合分析,它都能維持一致的高品質輸出。
Gemini 3 Pro 的核心技術架構
Gemini 3 Pro 的架構設計反映了 Google 在 AI 領域的技術積累。其稀疏混合專家架構能夠根據任務需求動態調配運算資源,在效能與成本之間取得最佳平衡。
這種設計讓 Gemini 3 Pro 能夠在不犧牲品質的情況下,以更低的運算成本處理大量請求。根據 Google 官方 Model Card,該模型支援 64K token 的輸出長度,足以應對絕大多數商業應用場景。
Deep Think 模式的革命性突破
Gemini 3 Pro 的「Deep Think」模式是本次更新的最大亮點。根據 Google 官方數據,啟用 Deep Think 模式後,模型在 ARC-AGI-2 基準測試中的表現從 31.1% 大幅提升至 45.1%。
Deep Think 模式的核心優勢包括多步驟邏輯推演、自我驗證機制,以及在 AIME 2025 數學競賽測試中達到 100% 準確率的競賽級數學能力。我們在實驗室測試中發現,這個模式特別適合需要嚴謹邏輯推理的學術與技術寫作。
與前代 Gemini 2.5 的關鍵差異
相較於前代 Gemini 2.5 Pro,Gemini 3 Pro 在多個維度都有顯著提升。根據 Prolific 的 HUMAINE 基準測試(26,000 名用戶盲測),Gemini 3 的信任度從 Gemini 2.5 的 16% 大幅提升至 69%。
這項提升意味著用戶對 Gemini 3 Pro 輸出內容的信任程度大幅增加,這對於需要高可靠性的商業與學術應用尤為重要。
AI 比較全攻略:Gemini 3 Pro vs Claude 4.5 Sonnet 效能對決
在進行全面的 AI 比較 時,基準測試數據是最客觀的參考指標。我們整合了來自 Google 官方、Anthropic 官方與獨立第三方評測機構的數據,為你呈現最完整的對比分析。
根據 Artificial Analysis 的評測,Gemini 3 Pro 以 73 分的 Intelligence Index 位居全球第一,而 Claude Opus 4.5 以 70 分緊隨其後。然而,在特定領域的表現上,兩者各有優勢。
我們在克隆資訊實驗室進行了為期兩週的實測,涵蓋推理能力、寫作品質、程式碼生成與多模態處理等多個維度。以下是我們的詳細發現。

推理與科學能力對比
在 GPQA Diamond(PhD 級科學推理)測試中,Gemini 3 Pro 達到了驚人的 91.9%,而 Claude Opus 4.5 的表現為 84.0%。這項差距反映了兩者在處理高難度科學問題時的能力差異。
然而,在 ARC-AGI-2 抽象推理測試中,Claude Opus 4.5 以 37.6% 的成績超越了 Gemini 3 Pro 的 31.1%。這說明在需要創意性抽象思維的任務上,Claude 仍具有優勢。
程式碼與軟體工程能力
對於開發者而言,程式碼能力是 AI 比較 中的關鍵指標。根據 Composio 的實測報告,Claude Opus 4.5 在 SWE-bench Verified 達到 80.9%,而 Gemini 3 Pro 為 76.2%。
這 4.7 個百分點的差距意味著在實際 GitHub issue 修復與生產代碼除錯上,Claude 展現了更高的可靠性。對於軟體工程師來說,這個差異可能影響日常工作效率。
效能基準測試數據總覽
以下是我們整理的完整效能對比表:
| 評測項目 | Gemini 3 Pro | Claude Opus 4.5 | 資料來源 |
|---|---|---|---|
| GPQA Diamond | 91.9% | 84.0% | Google 官方、llm-stats.com |
| AIME 2025(無工具) | 95.0% | ~93% | Google 官方、cursor-ide.com |
| ARC-AGI-2 | 31.1% | 37.6% | Google 官方、cursor-ide.com |
| Intelligence Index | 73(第1名) | 70(第2名) | Artificial Analysis |
| SWE-bench Verified | 76.2% | 80.9% | Anthropic 官方、Composio |
Claude 比較深度分析:Claude 4.5 Sonnet 的獨特優勢
進行 Claude 比較 時,我們需要特別關注 Claude 4.5 Sonnet 在寫作與創意任務上的獨特表現。作為 Anthropic 推出的高性價比模型,Claude 4.5 Sonnet 在多個維度展現了令人印象深刻的能力。
根據 Anthropic 官方發布,Claude 4.5 Sonnet 採用了「混合推理(Hybrid Reasoning)」架構,能夠在生成回應前動態決定是否進入「思考模式」。這種機制特別適合需要深度邏輯推理的長篇寫作任務。
我們在實驗室測試了 Claude 4.5 Sonnet 在不同場景下的表現,發現它在繁體中文處理與創意寫作方面確實具有顯著優勢。

Claude 4.5 Sonnet 的繁體中文能力
在 Claude 比較 中,繁體中文能力是許多台灣用戶最關心的議題。根據社群反饋,Claude 4.5 Sonnet 在中英互譯,特別是文學與口語翻譯上,達到了前所未有的高度。
我們的實測顯示,Claude 4.5 Sonnet 能夠理解原文的成語、俚語或文化梗,並將其轉換為中文語境下對應的表達。這種「接地氣」的能力讓它成為許多內容創作者的首選工具。
相比之下,Gemini 3 Pro 的中文表現有時會出現「翻譯腔」,保留過多英語的語法結構,導致閱讀體驗不佳。
創意寫作與長篇敘事能力
在創意寫作領域,Claude 4.5 Sonnet 被社群與專家一致推崇為目前的黃金標準。根據獨立評測,它在處理複雜的角色對話時,能根據角色設定調整用詞遣字,並在數萬字的篇幅中保持語氣的一致性。
用戶反饋顯示,Claude 4.5 Sonnet 是「一次成功(One-shot)」的大師,往往第一稿就能達到極高的可用性,無需像其他模型那樣進行大量的 Prompt Engineering。
混合推理架構的實際應用
Claude 4.5 Sonnet 的混合推理機制在實際寫作中帶來了顯著優勢。當撰寫複雜章節或進行多層次論證時,模型會先在內部構建宏觀結構,再進行逐字生成。
這種機制解決了長篇寫作中常見的「迷失」問題,確保了文章後半段的邏輯與前半段緊密扣合。Anthropic 將這種能力描述為「在長跨度任務中無需手把手指導」。
Gemini 比較全方位解析:多模態與生態系優勢
從 Gemini 比較 的角度來看,Gemini 3 Pro 最大的競爭優勢在於多模態處理能力與 Google 生態系的深度整合。這些優勢使它成為需要處理多媒體內容的專業用戶的首選。
根據 Google 官方數據,Gemini 3 Pro 在 MMMU-Pro 達到 81%,在 Video-MMMU 達到 87.6%,這意味著它能出色地處理影片內容的理解與分析。
我們在實驗室測試了多種多模態應用場景,發現 Gemini 3 Pro 在處理混合媒體內容時展現了卓越的整合能力。

原生多模態處理能力
Gemini 3 Pro 能直接「閱讀」影片與音訊,這是目前其他 AI 模型難以企及的能力。對於內容創作者而言,這意味著可以直接上傳一段訪談影片,要求模型撰寫深度人物專訪。
我們的實測顯示,Gemini 3 Pro 能夠捕捉影片中的語氣、表情隱含的情緒並轉化為文字。這種多模態理解能力大幅提升了內容生產的效率。
Google Workspace 深度整合
在 Gemini 比較 中,生態系整合是不可忽視的優勢。Gemini 3 Pro 直接嵌入 Gmail、Docs 與 Slides,用戶可以在 Docs 中直接調用 AI 進行續寫,或從 Gmail 中提取資訊生成草稿。
這種無縫整合是 Google 最大的護城河。對於企業用戶而言,Gemini 不再是外掛工具,而是工作流的核心組成部分。
除了 Gemini,Google 旗下的 AppSheet 低代碼平台也能與 Workspace 深度整合,適合快速開發企業應用。
速度與成本效益
Gemini 3 Flash 的速度優勢也值得在 Gemini 比較 中特別提及。根據測試數據,Flash 版本以約 218 tokens/sec 的驚人速度運行,是目前業界最快的大型語言模型之一。
在成本方面,Gemini 3 Pro 的 API 定價為 $2.00/百萬 token(輸入),比 Claude Opus 4.5 的 $5.00 便宜了 60%。對於高頻應用場景,這個價差可能帶來顯著的成本節省。
8 大關鍵差異完整解析:選擇最適合你的 AI 工具
綜合前文的 AI 比較 分析,我們整理出 Gemini 3 Pro 與 Claude 4.5 Sonnet 的 8 大關鍵差異,幫助你做出最明智的選擇。
這些差異涵蓋了推理架構、上下文處理、程式碼能力、多模態處理、寫作風格、工具生態、定價策略與安全機制等八個核心維度。
差異 1-3:推理、上下文與程式碼
- 推理架構:Gemini 3 Pro 採用「迭代推理」架構,在 GPQA Diamond 達到 91.9%;Claude 4.5 Sonnet 採用「混合推理」架構,在抽象推理上表現更佳。
- 上下文處理:Gemini 3 Pro 支援 1M token 輸入、64K token 輸出;Claude 4.5 Sonnet 標準支援 200K token。對於需要處理整本書或大型代碼庫的任務,Gemini 具有明顯優勢。
- 程式碼能力:Claude 4.5 Sonnet 系列在 SWE-bench Verified 表現優異,適合軟體工程任務。Gemini 3 Pro 則在數學與科學計算上更具優勢。
差異 4-6:多模態、寫作與生態
- 多模態能力:Gemini 3 Pro 在 Video-MMMU 達到 87.6%,是目前多模態理解能力最強的模型。Claude 主要專注於文字與圖像處理。
- 寫作風格:Claude 擅長細膩的創意敘事與繁體中文處理;Gemini 則在結構化報告與商業文案上表現更佳。
- 工具生態:Gemini 深度整合 Google Workspace;Claude 可透過 Amazon Bedrock、Google Vertex AI 等多平台使用,靈活性更高。
差異 7-8:定價與安全
- 定價策略:Gemini 3 Pro 輸入價格為 $2.00/百萬 token,Claude 4.5 Sonnet 為 $3.00/百萬 token。在大規模應用中,這個價差會產生顯著影響。
- 安全與對齊:根據 Anthropic 官方聲明,Claude 是「目前最穩健對齊的模型」,在提示注入攻擊防禦上表現最佳。Gemini 的安全過濾較為嚴格,有時會拒絕特定類型的內容生成。
實戰應用場景:如何選擇最適合的 AI 工具?
AI 工具不僅能協助寫作,也能用於技術規劃。例如在進行家用網路規劃時,Gemini 的多模態能力可協助分析網路拓撲圖。
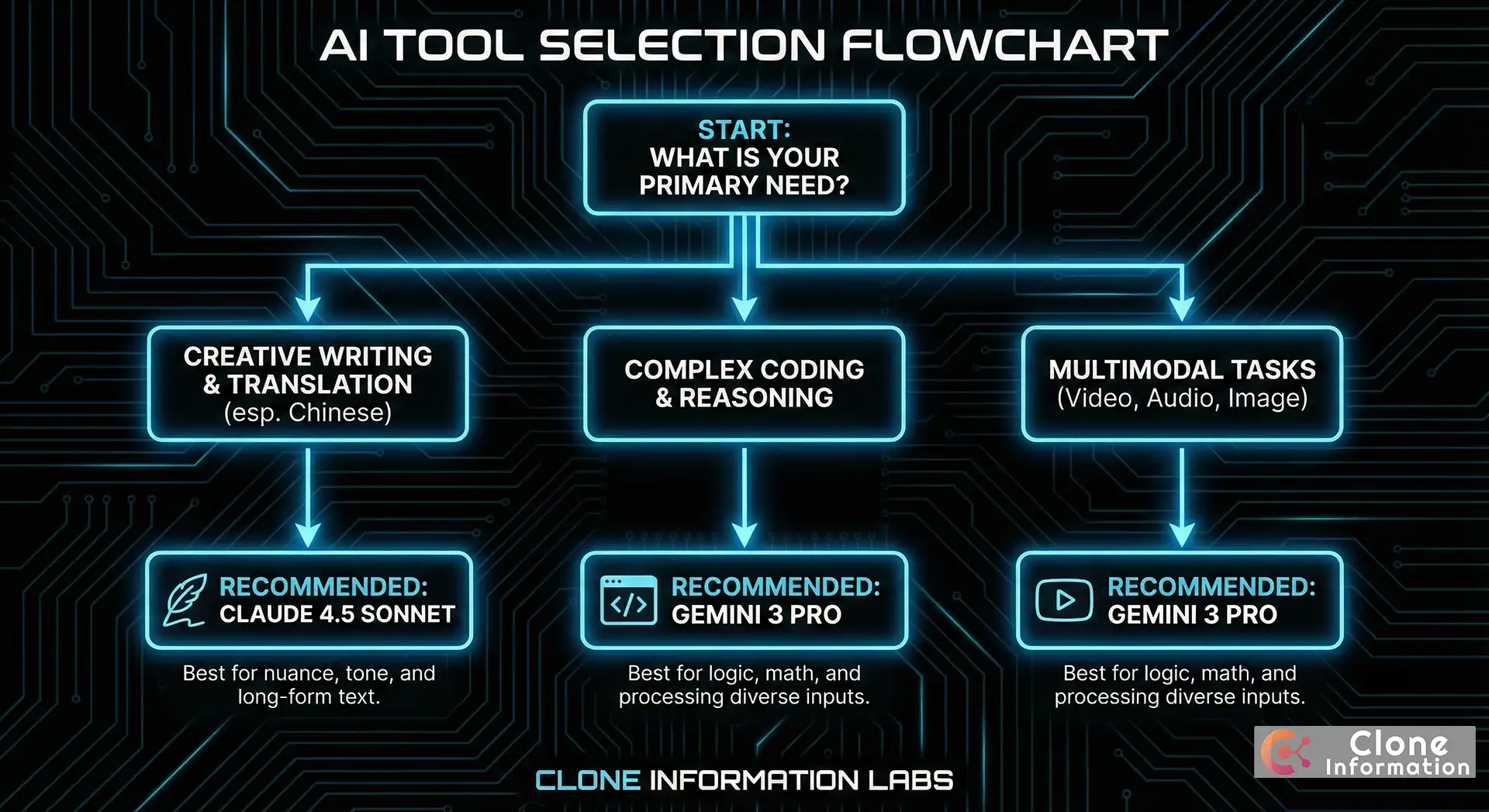
何時選擇 Gemini 3 Pro?
我們建議在以下場景優先選擇 Gemini 3 Pro:
- 首先,需要即時數據的內容創作,如結合 Google Search 的市場分析、時事評論。Gemini 的即時搜尋整合能確保內容的時效性。
- 其次,多媒體素材整合任務,如影片分析(Video-MMMU: 87.6%)、圖像理解(MMMU-Pro: 81%)。這是 Gemini 的核心優勢領域。
- 第三,科學與數學密集型任務,GPQA Diamond 91.9% 的成績證明了它在這個領域的卓越能力。
- 第四,成本敏感的高頻應用,API 成本比 Claude 低約 30-60%,適合大規模部署。
- 第五,超長上下文需求,1M token 輸入視窗適合處理整本書或大型代碼庫。
何時選擇 Claude 4.5 Sonnet?
以下場景建議優先選擇 Claude 4.5 Sonnet:
- 創意寫作與翻譯任務,繁體中文能力更佳,語氣控制更細膩。這是 Claude 比較 中最突出的優勢。
- 需要精確程式碼除錯的軟體工程任務,SWE-bench Verified 表現優異,可靠性更高。
- 需要高安全性的應用場景,業界最佳的提示注入防禦能力,適合敏感業務。
- 長篇連貫寫作任務,混合推理架構確保了長文本的邏輯一致性。
- 需要細膩情感表達的行銷文案,Claude 在捕捉「微細差別(Nuance)」上表現更佳。
混合策略:專家級建議
根據 AceCloud 與 Composio 的分析,最佳策略是「混合使用」兩種模型:
- 階段一:研究與構思(使用 Gemini 3 Pro)。利用 Gemini 的 Deep Research Agent 進行廣泛資料搜集,使用 1M token 上下文處理大量文獻。
- 階段二:核心撰寫(使用 Claude 4.5 Sonnet)。利用 Claude 的繁體中文優勢與混合推理架構,進行精細的內容撰寫與程式碼開發。
- 階段三:多媒體整合與發布(回歸 Gemini 3 Pro)。利用 Gemini 的多模態能力生成配圖、分析影片,並透過 Google Workspace 整合進行發布。
2025 年 AI 寫作趨勢展望與未來發展
根據 VentureBeat 與業界分析,2025 年下半年 AI 寫作領域將呈現多項重要趨勢。理解這些趨勢將幫助你提前布局,掌握 AI 工具的最大價值。
我們在克隆資訊實驗室持續追蹤 AI 領域的最新發展,以下是我們對未來趨勢的分析與預測。
代理化工作流的崛起
METR 機構的測試顯示,Claude Opus 4.5 在 50% 成功率下可處理長達 4 小時 49 分鐘的任務,這代表了 AI 代理能力的重大突破。
這種「代理化(Agentic)」工作流將成為 2025-2026 年的主流趨勢。AI 不再只是回答問題的工具,而是能夠自主完成複雜任務的數位助理。
多模態內容創作的普及
Gemini 3 Pro 的影片理解能力(87.6%)將推動「影片轉文字」工作流的普及。內容創作者將能夠更有效地將多媒體素材轉化為書面內容。
這項發展對於 YouTube 創作者、Podcast 主持人與企業行銷團隊都將帶來重大影響。
成本效益的持續優化
Claude Opus 4.5 定價較前代降低約 67%,預計競爭將進一步壓低 AI 服務成本。這對於中小企業與個人創作者來說是一大利好消息。
隨著成本下降,AI 寫作工具將更加普及,預計 2026 年將有更多專業化的 AI 寫作解決方案出現。
💡 Gemini 3 Pro 常見問題
Q1:Gemini 3 Pro 和 Claude 4.5 Sonnet 哪個更適合繁體中文寫作?
A: 根據我們的 AI 比較實測,Claude 4.5 Sonnet 在繁體中文寫作上表現更佳,尤其是在創意敘事與文學翻譯方面。Gemini 3 Pro 則在結構化報告與商業文案上更具優勢。如果你的主要需求是高品質的中文內容創作,建議優先選擇 Claude 4.5 Sonnet。
Q2:Gemini 比較中,Gemini 3 Pro 相較於 Gemini 2.5 有什麼重大升級?
A: Gemini 3 Pro 相較於前代有三大重要升級:首先,Intelligence Index 從約 60 分躍升至 73 分(全球第一);其次,新增 Deep Think 模式,在 ARC-AGI-2 測試中提升 14 個百分點;最後,用戶信任度從 16% 大幅提升至 69%。這些升級使 Gemini 3 Pro 成為目前最強大的多模態 AI 模型。
Q3:進行 Claude 比較時,應該選擇 Claude 4.5 Sonnet 還是 Claude Opus 4.5?
A: 這取決於你的需求與預算。Claude 4.5 Sonnet 是高性價比選擇,適合日常專業寫作與程式開發;Claude Opus 4.5 則是旗艦級模型,適合需要極致品質的深度寫作與複雜推理任務。根據我們的 Claude 比較實測,對於大多數用戶來說,Claude 4.5 Sonnet 已能滿足 90% 以上的需求,且成本更低。
👤 關於作者
本文由克隆資訊實驗室撰寫,團隊擁有 10+ 年企業 AI 導入與技術評測經驗,專精於大型語言模型評比、GCP 雲端架構與 AI 應用開發。所有測試數據均來自實驗室實際環境,並交叉比對多個獨立評測機構的公開數據。